

This episode unpacks how AI crawlers are pulling content from blogs, news sites, and forums without credit, clicks, or compensation. We explore the real-world impact on web monetization and walk through an illustrative idea called AI Gatepass, a thought experiment on how access, control, and payments could be reimagined for the AI era.

Imagine running a blog, news site, or review page. You write helpful content, place ads, and include affiliate links to earn commissions. Now picture this: someone asks ChatGPT, Siri, or Google's Gemini a question, and instead of sending them to your website, the AI simply answers directly, pulling information straight from your page.
No clicks. No ads viewed. No sales commissions earned. Your work is used—but you're left unpaid.

So how did we end up here? Let’s break it down.
Why AI Needs Your Content
AI tools don’t just become smart overnight. They read and digest massive amounts of online content—from your blog posts and product reviews to Wikipedia articles and news reports. These AI systems continuously crawl the web, copying your content to provide timely answers.
Think of it like a giant, silent photocopier scanning and storing every word you publish, ready to deliver answers on demand without ever sending visitors your way.
Real-Time Data: AI’s Other Essential Ingredient
Besides historical data, AI also requires constant updates to remain relevant and effective. Real-time data like breaking news, weather updates, stock prices, and even personal emails help AI become more personalized, accurate, and immediately useful. Without continuous access to fresh data, tools like GPT, Siri, or Google’s Gemini could quickly become outdated and less helpful in everyday tasks.
The Problem First: What’s Really Going On?
Right now, AI tools are learning from the internet—your blogs, your articles, your posts—without asking, without paying, and without giving credit. Once a model reads your content, it can use that knowledge forever. There’s no log. No trail. No attribution.
And here’s the kicker: when your original work helps train the next generation of AI tools, you never even know it happened.
At the same time, website owners are waking up. They’re realizing that AI bots are visiting their pages, not as readers, but as data harvesters. Crawlers are hoovering up everything in sight—and you’re left with zero insight, zero control, and zero compensation.
Cloudflare recently stepped in, blocking AI scrapers by default and rolling out a “Pay Per Crawl” system. Big names like Reddit and Stack Overflow are onboard. But that only covers a slice of the web. Independent creators? Smaller devs? Everyone else? Still exposed.
We don’t think this system should be limited to the top 1% of websites.
We want to open that door to everyone—and give power back to the people who make the internet valuable.
Let’s Build This Startup Together (Right Here in the Blog): Let's call it "AI-Gatepass"

Picture this: you and I, laptops open, throwing ideas around at a coffee shop or over Slack. We’re not just daydreaming—we’re shaping a tool the internet desperately needs. One that gives power back to the people who actually make the web what it is: creators like us.
Let’s sketch it out. You chime in where it clicks. I’ll keep typing.
Step 1: Add One Script. That’s It.
First things first: it should take you less time to install than it takes to reheat your coffee. We drop a tiny JavaScript snippet into your site. Done dev team needed. No multi-step onboarding. Just plug it in, and instantly your site becomes AI-aware.
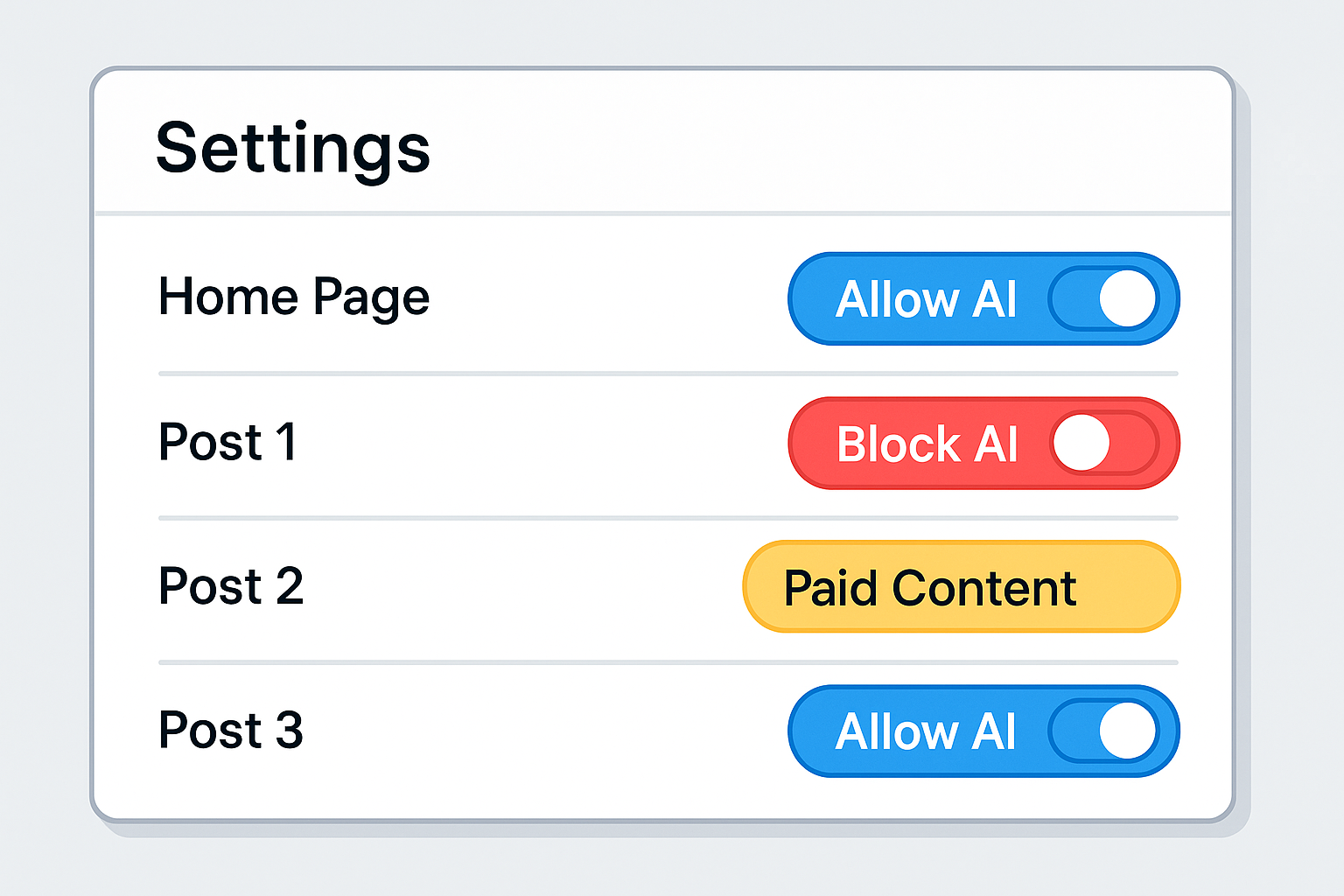
Step 2: Flip the Power Dynamic, create a clean, no-nonsense dashboard. Together, we decide:
- "Yep, let AI read this page."
- "Nope, block this one."
- "This section? That’s premium."
It’s as easy as flipping a switch.
Step 3: Bots Ask. We Decide.
Every time a crawler knocks, AI-Gatepass steps in like a friendly bouncer:
- Are you approved?
- Did you pay?
- What pages can you access?
If it checks out, it gets limited, logged access. If not? Sorry, door’s closed. But we can go even further. Rather than letting AI crawl multiple pages to find one answer, we can handle the query ourselves—acting like a smart RAG layer for the web. This isn’t 2008. Bots don’t need to crawl every page to find one fact. They can ask direct questions—we return what’s allowed, and only that. We’re not just blocking or allowing. We’re optimising. Filtering. Curating. Imagine the crawler gets what it needs without eating your whole sitemap. Efficient for them. Fair to us.

Reality Check: We’re Not Cloudflare (And That’s Okay)
Let’s talk real.
Recently, Cloudflare announced they’re blocking AI bots by default and letting publishers charge for access via their new “Pay Per Crawl” feature. Big sites like Reddit, BuzzFeed, Time, and Stack Overflow are already on board.
That’s a huge step. For the first time, AI scrapers are being asked: “Did you pay?” before they can access anything. And if they didn’t, the door stays closed.
It’s smart. It’s bold. And honestly—it’s the first true sign that content creators might have a fighting chance.
But here’s the catch: Cloudflare powers less than 20% of the web. And their focus is on big media sites and publishers—not independent creators, developers, or smaller tools.
So while they lit the torch, they’re not handing it out.
And here’s the other problem: we’re not Cloudflare, and we don’t yet have the stats, reach, or muscle to walk into OpenAI’s office and say, “Use our API.”
So how do we get there?
Strategy #1: Pay Creators First
We flip the model. We invest upfront and pay creators right now when AI bots visit their content. Even if AI companies haven’t paid us yet. It’s a bold move—but it builds trust. It grows adoption. It gives us real-world stats. And when we’ve built that critical mass? That’s when we knock on the AI giants’ doors—not with a pitch deck, but with data, adoption, and leverage.
Eventually, we can say: “Use our API—or be cut off.”
Strategy #2: One Key to Rule the Chaos
Let’s connect the dots. Right now, the AI blocker world is a mess—dozens of tools, APIs, paywalls, token systems. Everyone’s building their own fence, but no one’s talking to each other.
Now imagine we’re building something like Siri, GPT, or a personal assistant tool. It hits three sites. All blocked — different systems, different keys. The user hears, “Sorry, can’t access that,”.
This is what happens without a common system.
So we build one:
- We track every new AI-blocker.
- Create accounts.
- Collect API keys.
- Build connectors.
Everything routes through us. Now devs only need to plug in once. AI bots only talk to one system. We simplify the mess—and that makes us essential.
This also makes room for hobbyists, startups, and custom AI agents—not just big players. Whether you're using GPT, MPC, or building your own browser assistant, you plug into one place and get universal access.
Bonus Idea: What If We Could Protect Original Ideas Too?
Let’s stretch this vision further—because protecting access is one thing, but what about protecting originality?
📌 Here's how it could work:
- Submit: A creator uploads their work—blog post, illustration, essay, etc.
- Review: Our team (using a Wikipedia-style moderation process) checks the content for originality and relevance.
- Verify: We run AI tools to confirm uniqueness through semantic matching and fingerprint analysis.
- Register: Approved entries are timestamped and locked into a public, tamper-proof registry.
- Monitor: The system compares new AI outputs (like GPT or Claude) against the registry. If there’s a strong match, it gets flagged.
- Detect & Probe (New): Our system can actively generate test queries and send them to AI chatbots. If their response is over 90% semantically similar to a registered entry, we log the match along with the exact query used.
- Flag (New): Those matches can serve as documented case studies—potential evidence for negotiation, compensation, or even legal action.
- Link: The system provides a cryptographically signed link to the original entry—verifiable proof of authorship. This allows AI companies to trace the origin and attribute content responsibly.
- Monetize: AI companies pay to access the registry. Part of that payment is routed back to the content creator as a royalty or licensing fee.
This creates a new incentive: models that want to avoid lawsuits or content disputes will have a strong reason to check against this registry before generating. Creators can choose to retain, license, or sell their rights—just like digital art or music rights today. This isn’t about censorship. It’s about traceability, transparency, and giving creators credit where it’s due.
It’s also a practical legal utility: when future lawsuits or disputes arise, our system becomes the go-to place to verify who created what, when, and how it might have influenced a model. More importantly, it offers historical traceability—allowing content owners to check if, when, and how their work was used by specific AI models in past generations.
